一、安装 CentOS 6 & 基本配置
win10通过VMware安装CentOS6.5 - 简书
https://www.jianshu.com/p/9d5b9757a1ef
1、关闭防火墙
1 | service iptables stop |
2、创建普通用户
1 | useradd Ace |
3、创建软件存储文件夹,并更改所有权
1 | mkdir /opt/software /opt/module |
4、用户添加到 sudoers
1 | vi /etc/sudoers |
5、改 Hosts
1 |
|
6、改静态 ip
vim /etc/sysconfig/network-scripts/ifcfg-eth0
1 | DEVICE=eth0 |
【创建新虚拟机,下面的都要做一遍,可以写脚本解决(看下面,推荐)】
6、改 ip 地址(同上6)
vim /etc/sysconfig/network-scripts/ifcfg-eth0
1 | IPADDR=192.168.87.100 # 改成对应的 |
7、改主机名
vim /etc/sysconfig/network
1 | HOSTNAME=hadoopxxx |
8、删除多余网卡
vim /etc/udev/rules.d/70-persistent-net.rules
1 | # 第一行删掉(只保留一个网卡就行,注释也删掉,手动删的话记得和后面脚本的行数要对应上) |
9、拍快照,克隆
【脚本】
- 分发脚本 xsync
vim xsync
1 |
|
移动到bin目录下,sudo mv xsync /bin
安装rsync,sudo yum install -y rsync
改权限,chmod +x xsync
- 执行相同命令脚本
1 |
|
移动到/bin,改权限
- 自动配置网络脚本
1 |
|
改权限,chmod +x change_network
二、安装 JAVA 和 Hadoop
1、下载/上传 java 和 hadoop 的包到 /opt/software
2、解压 java 和 hadoop 到 /opt/module
3、安装(配置环境变量)
1 | sudo vim /etc/profile |
4、测试安装情况
执行下面命令后,能出现版本号即为成功
1 | $ java -version |
5、使用 xsync 同步到多个机器上
三、Hadoop 配置
Apache Hadoop 3.2.1 – Hadoop: Setting up a Single Node Cluster.
- 安装插件
1 | $ sudo yum install ssh |
- 环境配置
vim etc/hadoop/hadoop-env.sh
1 | export JAVA_HOME=/your-java-home-path |
3.1 本地运行模式
1 | $ mkdir input |
3.2 伪分布式
1、配置
vim etc/hadoop/core-site.xml
1 | <configuration> |
etc/hadoop/hdfs-site.xml
1 | <configuration> |
暂时不配置 yarn 了
etc/hadoop/yarn-env.sh
1 | export JAVA_HOME=/opt/module/jdk1.8.0_144 |
2、设置免密码登录
1 | $ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa |
3、执行
Format the filesystem:
1
$ bin/hdfs namenode -format
Start NameNode daemon and DataNode daemon:
1
$ sbin/start-dfs.sh
The hadoop daemon log output is written to the
$HADOOP_LOG_DIRdirectory (defaults to$HADOOP_HOME/logs).Browse the web interface for the NameNode; by default it is available at:
- NameNode -
http://localhost:9870/
- NameNode -
Make the HDFS directories required to execute MapReduce jobs:
1
2$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/<username>Copy the input files into the distributed filesystem:
1
2$ bin/hdfs dfs -mkdir input
$ bin/hdfs dfs -put etc/hadoop/*.xml inputRun some of the examples provided:
1
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
Examine the output files: Copy the output files from the distributed filesystem to the local filesystem and examine them:
1
2$ bin/hdfs dfs -get output output
$ cat output/*or View the output files on the distributed filesystem:
1
$ bin/hdfs dfs -cat output/*
When you’re done, stop the daemons with:
1
$ sbin/stop-dfs.sh
3.3 完全分布式
同步两个软件,/etc/profile
3.3.1 集群配置
- 集群部署规划
NN 1个; 2NN 1个;RM 1个;DN 3个、NM 3个 —— 最少共需六台机器,但是开不起那么多个虚拟机,因此按下表进行合并配置
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode, DataNode | DataNode | SecondaryNameNode, DataNode |
| YARN | NodeManager | ResourceManager, NodeManager | NodeManager |
- 配置集群
1)核心配置文件
配置etc/hadoop/core-site.xml
1 | <!-- 指定HDFS中NameNode的地址 --> |
2)HDFS配置文件
配置``etc/hadoop/hadoop-env.sh`
1 | export JAVA_HOME=/opt/module/jdk1.8.0_144 |
配置etc/hadoop/hdfs-site.xml
1 | <property> |
3)YARN配置文件
配置etc/hadoop/yarn-env.sh
1 | export JAVA_HOME=/opt/module/jdk1.8.0_144 |
配置etc/hadoop/yarn-site.xml
1 | <!-- Reducer获取数据的方式 --> |
4)MapReduce配置文件
配置etc/hadoop/mapred-env.sh
1 | export JAVA_HOME=/opt/module/jdk1.8.0_144 |
配置etc/hadoop/mapred-site.xml
1 | $ cp mapred-site.xml.template mapred-site.xml |
- 在集群上分发配置好的Hadoop配置文件
1 | $ xsync /opt/module/hadoop-2.7.2/ |
3.3.2 集群单点启动
1)如果集群是第一次启动,需要格式化NameNode
1 | $ hadoop namenode -format |
2)在 hadoop102 上启动 NameNode
1 | $ hadoop-daemon.sh start namenode |
3)在 hadoop102、hadoop103、hadoop104 上分别启动DataNode
1 | $ hadoop-daemon.sh start datanode |
4)在 hadoop104 上启动 secondarynamenode
1 | $ hadoop-daemon.sh start secondarynamenode |
5)查看服务启动情况 jps
1 | [hadoop102]$ jps |
3.3.3 集群一键启动
- 配置机器间 ssh 无密登录
「方法1:共用一个秘钥」
1 | # 生成秘钥 |
「方法2:每个机器单独生成秘钥」
1 | # 在每个机器上生成秘钥(每个机器执行一遍) |
- 添加机器名,配置
etc/hadoop/slaves,并同步到其他机器(xsync)
1 | hadoop102 |
- 启动
1 | [hadoop102]$ start-dfs.sh |
- 测试(单词计数)
1 | # 创建一个文件夹 wcinput,里面放一个文件,添加计数文件中的内容,如: |
- 停止
1 | [hadoop102]$ stop-dfs.sh |
3.3.4 配置历史服务器 & 日志聚集
- 配置
etc/hadoop/mapred-site.xml,添加:
1 | <!-- 历史服务器端地址 --> |
- 配置
etc/hadoop/yarn-site.xml
1 | <!-- 日志聚集功能使能 --> |
[分发配置]
启动
1 | [hadoop102]$ start-dfs.sh |
- 查看
- 打开 yarn web http://hadoop103:8088/
- 打开 history,再点 log 就能看到任务具体的日志信息了
3.3.5 集群时间同步
1)检查 ntp 是否安装
查看 ntp 包(切换到 root 用户)
1 | [root@hadoop102 ~]# rpm -qa | grep ntp |
如果没有这两个服务要安装一下
1 | yum install -y ntp |
先停止 ntp 服务
1 | # 查看 ntpd 服务是否在运行 |
2)修改ntp配置文件/etc/ntp.conf
1 | # 修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间) |
3)修改/etc/sysconfig/ntpd文件
1 | 增加内容如下(让硬件时间与系统时间一起同步) |
4)重新启动ntpd服务
1 | $ service ntpd status |
5)设置ntpd服务开机启动
1 | [hadoop102]$ chkconfig ntpd on |
6)其他机器配置(必须root用户)
在其他机器配置10分钟与时间服务器同步一次
1 | $ crontab -e |
测试(修改任意机器时间),十分钟后查看机器是否与时间服务器同步
1 | $ date -s "2017-9-11 11:11:11" |
7)若主机时间不对
1 | $ service ntpd stop |
3.4 常用端口记录
| 组件 | 节点 | 默认端口 | 配置 | 用途说明 |
|---|---|---|---|---|
| HDFS | DataNode | 50020 | dfs.datanode.ipc.address | ipc服务的端口 |
| HDFS | NameNode | 50070 | dfs.namenode.http-address | http服务的端口,可查看 HDFS 存储内容 |
| HDFS | NameNode | 8020 | fs.defaultFS | 接收Client连接的RPC端口,用于获取文件系统metadata信息 |
| YARN | Resource Manager | 8088 | yarn.resourcemanager.webapp.address | Yarn http服务的端口 |
| HBase | Master | 16000 | Master RPC Port(远程通信调用) | |
| Master | 16010 | Master Web Port | ||
| Regionserver | 16020 | Regionserver RPC Port | ||
| Regionserver | 16030 | Regionserver Web Port | ||
| Spark | 4040 | 查看 Spark Job |
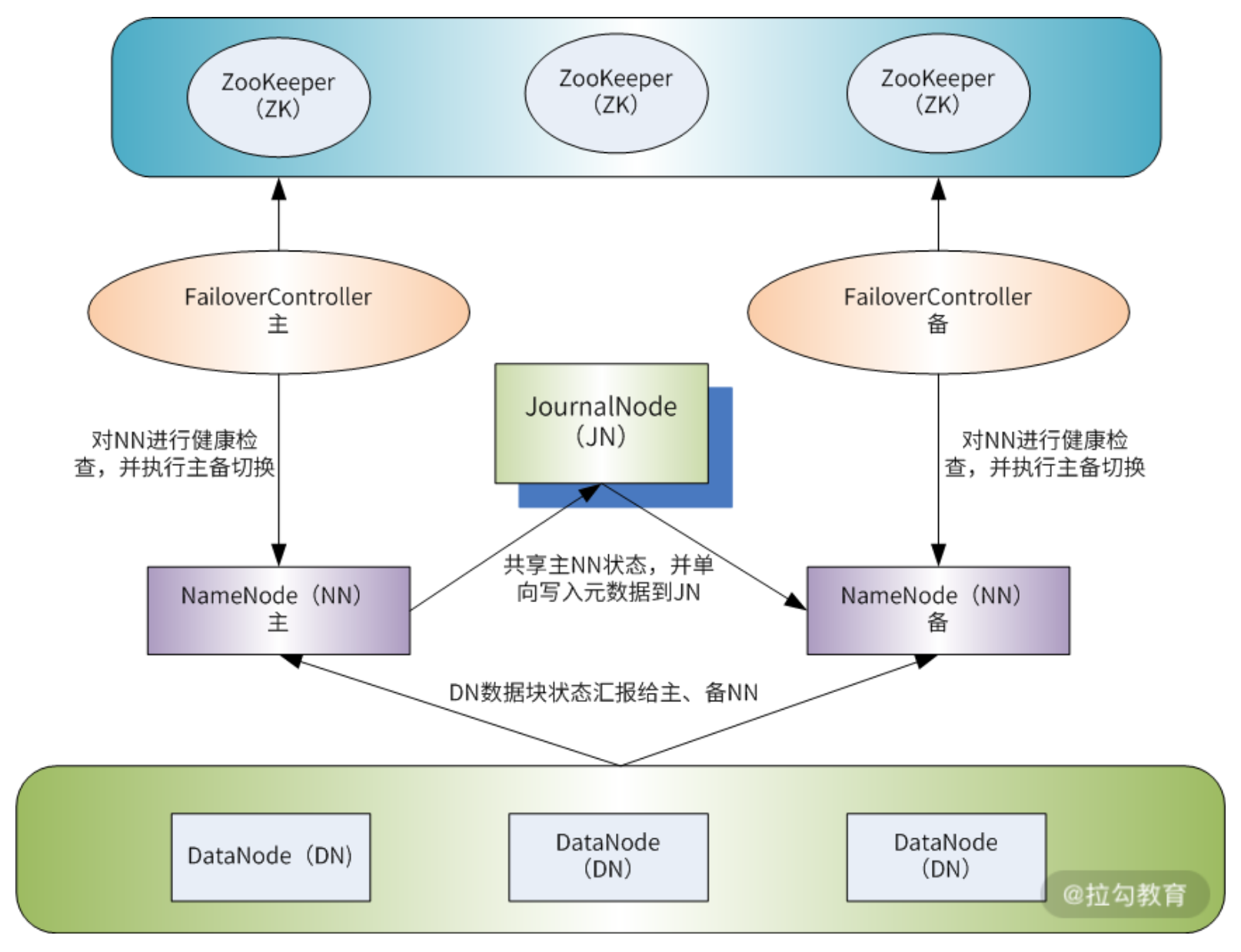
3.5 HA
- 配置两个 NameNode
- 配置 JournalNode 用于将 Active NN 的数据 同步到 Standby NN 上「解决元数据同步的问题」
- 配置 Zookeeper,解决主备 NN 切换的问题,防止脑裂
- 在 NN 上启动 failoverController(zkfc),作为 Zookeeper 的客户端,实现与 zk 集群的交互和监测
3.6 其他
3.6.1 增加 Yarn 队列
https://blog.csdn.net/lijingjingchn/article/details/84876193
修改 etc/hadoop/capacity-scheduler.xml
1 | <property> |
刷新配置:
1 | bin/yarn rmadmin -refreshQueues |
注意:
热更新只能增加队列,要删除队列只能重启 RM。
https://stackoverflow.com/questions/42589764/how-to-delete-a-queue-in-yarn
3.6.2 配置 node label
官方文档参考:
https://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/NodeLabel.htmlcloudera 文档参考(推荐)
https://docs.cloudera.com/HDPDocuments/HDP2/HDP-2.6.5/bk_yarn-resource-management/content/configuring_node_labels.html
1)先创建 node-label-conf 存放的路径
1 | hadoop fs -mkdir /node-labels-conf |
2)配置yarn-site.xml ,增加
1 | <!--开启node label --> |
刷新
1 | bin/yarn rmadmin -refreshQueues |
3)重启 RM
4)添加 label
1 | # 添加 |
5)给 node 打 label
1 | yarn rmadmin -replaceLabelsOnNode "hadoop102=my_label_test" |
6)将队列与 label 关联
1 | # 遵循层级配置 |
1 | # 刷新队列 |
7)查看效果
1 | [Ace@hadoop102 hadoop]$ yarn node -list |
8)测试
1 | hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount -D mapreduce.job.queuename=myqueue -D node_label_expression=my_label_test /wcinput /output/xxx |
2.7.2 版本有超多bug & 不完善
a) 设置队列后 web ui 没有分组显示
b) 为了能在指定 label node 上运行,需要把默认队列的 capacity 和 max-capacity 都设为0。但是这样会导致只能起一个 AM(一个 job)
共享label
- There are two kinds of node partitions:
- Exclusive: containers will be allocated to nodes with exactly match node partition. (e.g. asking partition=“x” will be allocated to node with partition=“x”, asking DEFAULT partition will be allocated to DEFAULT partition nodes).
- Non-exclusive: if a partition is non-exclusive, it shares idle resource to container requesting DEFAULT partition.
1 | yarn rmadmin -addToClusterNodeLabels "label_1(exclusive=true/false)" |
3.6.3 添加 Prometheus 监控
3.6.3.1 HDFS 监控
https://www.jesseyates.com/2019/03/03/hdfs-blocks-missing-vs-corrupt.html
- 配置
etc/hadoop/hadoop-env.sh,添加如下内容
1 | # add prom |
- 创建
${HADOOP_HOME}/namenode.yml
1 | lowercaseOutputName: true |
重启 HDFS(Namenode)
3.6.3.2 Yarn 监控
- 配置
etc/hadoop/hadoop-env.sh,添加如下内容
1 | # add prom |
- 创建
${HADOOP_HOME}/capacity-scheduler.xml(这里面有啥区别??)
1 | lowercaseOutputName: true |
- 重启 Resource Manager
- 查看效果:http://hadoop104:8042/jmx
可能有用的参数:
1 | }, { |
==看到的内存比实际的多?==
1 | # HELP hadoop_nodemanager_availablegb AvailableGB (Hadoop<service=NodeManager, name=NodeManagerMetrics><>AvailableGB) |
更细粒度监控
可以通过这个地址看到 json / xml 格式的监控信息
1 | http://<rm http address:port>/ws/v1/cluster/scheduler |
3.6.4 NM 内存容量动态更新
1 | yarn rmadmin -updateNodeResource ${HOSTNAME}:45454 53248 28 |
3.6.5 hdfs balancer
Increasing HDFS Balancer Performance
3.6.6 Nodemanager 重启恢复
Enabling NM Restart
Step 1. To enable NM Restart functionality, set the following property in conf/yarn-site.xml to true.
| Property | Value |
|---|---|
yarn.nodemanager.recovery.enabled |
true, (default value is set to false) |
Step 2. Configure a path to the local file-system directory where the NodeManager can save its run state.(本地文件目录)
| Property | Description |
|---|---|
yarn.nodemanager.recovery.dir |
The local filesystem directory in which the node manager will store state when recovery is enabled. The default value is set to $hadoop.tmp.dir/yarn-nm-recovery. |
Step 3. Configure a valid RPC address for the NodeManager.
| Property | Description |
|---|---|
yarn.nodemanager.address |
Ephemeral ports (port 0, which is default) cannot be used for the NodeManager’s RPC server specified via yarn.nodemanager.address as it can make NM use different ports before and after a restart. This will break any previously running clients that were communicating with the NM before restart. Explicitly setting yarn.nodemanager.address to an address with specific port number (for e.g 0.0.0.0:45454) is a precondition for enabling NM restart. |
1 | <!-- Yarn Restart --> |
需要手动创建这个文件夹:
1 | mkdir /data1/eadop/hadoop-tmp/yarn-nm-state |
其他服务:
1 | org.apache.hadoop.service.ServiceStateException: org.fusesource.leveldbjni.internal.NativeDB$DBException: IO error: /data1/eadop/hadoop-tmp/nm-aux-services/mapreduce_shuffle/mapreduce_shuffle_state/LOCK: No such file or directory |
1 | mkdir nm-aux-services |
3.6.7 使用同一份keytab
改yarn-site.xml配置
1 | <property> |
其他:还以把一堆keytab合并?里面有很多的principal
3.7 升级 Yarn
3.7.1 升级版本到 2.8.5
需要修改的文件
yarn-env.shyarn-site.xmlslavescore-site.xmlhadoop-env.shhdfs-site.xml
测试能否只升级 RM,不升级 NM(可以)
3.8 Hadoop 进阶命令使用
集群间数据平衡:
1 | > nohup hdfs balancer -D "dfs.balancer.movedWinWidth=300000000" -D "dfs.datanode.balance.bandwidthPerSec=2000m" -threshold 1 > hadoop-hadoop-balancer-hadoop-0018.log & |
节点内各个磁盘的数据平衡:
1 | > hdfs diskbalancer -plan IP -bandwidth 1000 -v 2> /dev/null | egrep ^/ | xargs hdfs diskbalancer -execute |
接上,查看磁盘平衡情况/进度:
1 | > hdfs diskbalancer -query IP |
YARN资源置空(这里多说一下,资源置空我们在生产环境是有些情况需要把这个node下线,但是此时此刻正有任务在运行,资源置空之后,UI上面会显示这个资源是负值,等正在运行的任务运行完成之后就不会再提交到这个node上了,就可以下线了)
- 注意这个PORT是UI页面上的Node Address,不是Node HTTP Address
1 | > yarn rmadmin -updateNodeResource IP:PORT 0 0 |
HDFS高可用Namenode主从切换:
- nn1,nn2这两个是你集群配置文件配置高可用时指定的别名,需要用你自己的
1 | > hdfs haadmin -failover nn2 nn1 |
HDFS退出安全模式
1 | > hadoop dfsadmin -safemode leave |
HDFS动态生效datanode/namenode配置:
- status:查看动态生效配置状态
- start:执行动态生效配置动作
- properties:查看修改了哪些配置与正在运行的不一样
1 | > hdfs dfsadmin -reconfig datanode IP:PORT status|start|properties |
3.9 监控
3.# 技术文章
四、Zookeeper 配置
4.1 本地模式
1、安装前准备
- 安装Jdk
- 拷贝Zookeeper安装包到Linux系统下
- 解压到指定目录
1 | tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/ |
2、配置修改
- 修改
conf/zoo_sample.cfg
1 | cp zoo_sample.cfg zoo.cfg |
- 修改 zoo.cfg 文件
1 | dataDir=/opt/module/zookeeper-3.4.10/zkData |
并创建 zkData 文件夹
3、操作Zookeeper
- 启动Zookeeper
1 | $ bin/zkServer.sh start |
- 查看进程是否启动
1 | $ jps |
- 查看状态:
1 | $ bin/zkServer.sh status |
- 停止Zookeeper
1 | $ bin/zkServer.sh stop |
4.2 集群模式
1、配置
- 修改 zoo.cfg 文件
1 | server.2=hadoop102:2888:3888 |
- 创建
zkData/myid,每个机器写不同的,要和前面的对应上
1 | $ vim zkData/myid |
- 配置
bin/zkEnv.sh
1 | # 替换前 |
- 同步 xsync
2、启动
1 | # 每个机器都要单独启动 |
仅启动一台机器时:
1 | $ ./zkServer.sh status |
启动两台机器(超过半数):
1 | $ ./zkServer.sh status |
3、集群脚本
1 |
|
4.3 客户端操作
- 启动
1 | $ bin/zkCli.sh |
- 执行
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path [watch] | 使用 ls 命令来查看当前znode中所包含的内容 |
| ls2 path [watch] | 查看当前节点数据并能看到更新次数等数据 |
| create | 普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
| get path [watch] | 获得节点的值 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| rmr | 递归删除节点 |
五、Kakfa 配置
5.1 环境准备
- 在 hadoop102 103 104 上均安装 Kafka
- jar 包下载 https://kafka.apache.org/downloads
- 命名中有两个版本号,第一个为 scala 版本,第二个是 kafka 版本
5.2 集群配置
- 修改
config/server.properties
1 | # broker的全局唯一编号,不能重复 |
分发安装包到所有物理机上 xsync
将 hadoop103 104 上
config/server.properties中的broker.id=x进行修改
单点启动 / 停止
依次在 hadoop102、hadoop103、hadoop104 节点上启动/停止 kafka,执行下面的命令
1 | # 启动 |
群起 / 群停
由于 Kafka 中没有给集群启动停止的脚本,需要自己写kk-all.sh
需要注意:要先在 ~/.bashrc 中配置 java 环境变量(xsync)
1 | # JAVA_HOME |
1 |
|
启动/停止 Kafka:(记得先启动 Zookeeper)
1 | $ ./kk-all.sh start |
5.3 命令行操作
- 查看当前服务器中的所有 topic
1 | $ bin/kafka-topics.sh --zookeeper hadoop102:2181 --list |
- 创建 topic
1 | $ bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 3 --partitions 1 --topic first |
--replication-factor 定义副本数;--partitions 定义分区数
- 删除 topic
1 | $ bin/kafka-topics.sh --zookeeper hadoop102:2181 --delete --topic first |
- 查看某个 Topic 的详情
1 | $ bin/kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic first |
- 发送消息
1 | $ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first |
- 消费消息
1 | $ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first |
--from-beginning 会把 first 主题中以往所有的数据都读取出来
六、Spark 配置
6.1 环境准备
下载地址:https://archive.apache.org/dist/spark/
有两种版本,hadoop 版下载就能用,不依赖其他组价;without-hadoop 需要依赖已有的 hadoop 组件
spark-2.3.2-bin-hadoop2.7.tgz
spark-2.3.2-bin-without-hadoop.tgz
6.2 本地模式 Local
- Jar
解压后进入 Spark 根目录执行(一个算 PI 的程序):
1 | bin/spark-submit \ |
输出结果:
1 | # 一大堆迭代过程 |
可以通过访问 http://hadoop102:4040 查看任务运行情况
「问题」:运行结束这个页面就关闭了,不能查历史任务执行情况
「解决」:添加 Spark History Server
- Spark-shell
进入 Spark-shell,bin/spark-shell
1 | # 创建两个文件,里面输入几行单词 |
6.3 Standalone 模式
构建一个由 Master + Slave 构成的 Spark 集群,Spark 运行在集群中。
这个要和 Hadoop 中的 Standalone 区别开来.这里的 Standalone 是指只用 Spark 来搭建一个集群, 不需要借助其他的框架.是相对于 Yarn 和 Mesos 来说的.
6.3.1 Spark server配置
1、进入配置文件目录conf,配置spark-evn.sh
1 | cd conf/ |
在 spark-env.sh 文件中配置如下内容:
1 | SPARK_MASTER_HOST=hadoop102 |
2、修改 slaves 文件,添加 worker 节点
1 | cp slaves.template slaves |
3、修改 sbin/spark-config.sh,添加 JAVA_HOME (防止 JAVA_HOME is not set 报错)
1 | export JAVA_HOME=/opt/module/jdk1.8.0_144 |
4、分发spark-standalone
5、启动 Spark 集群
1 | sbin/start-all.sh |
6、网页查看信息:http://hadoop102:8080/
7、测试
1 | bin/spark-submit \ |
6.3.2 spark-history-server
在 Spark-shell 没有退出之前,看到正在执行的任务的日志情况:http://hadoop102:4040. 但是退出之后,执行的所有任务记录全部丢失
所以需要配置任务的历史服务器, 方便在任何需要的时候去查看日志。
- 配置spark-default.conf文件,开启 Log
1 | cp spark-defaults.conf.template spark-defaults.conf |
在 spark-defaults.conf 文件中, 添加如下内容:
1 | spark.eventLog.enabled true |
注意:
hdfs://hadoop201:9000/spark-job-log 目录必须提前存在, 名字随意
- 修改spark-env.sh文件,添加如下配置
1 | export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://hadoop102:9000/spark-job-log" |
- 分发配置文件
- 启动历史服务
- 需要先启动 HDFS
$HADOOP_HOME/sbin/start-dfs.sh - 然后再启动:
sbin/start-history-server.sh
- 需要先启动 HDFS
ui 地址: http://hadoop102:18080
6.4 Yarn 模式
6.4.1 spark server 配置
- 修改
${HADOOP_HOME}/etc/hadoop/yarn-site.xml(仅虚拟机中配置,防止内存不够)
1 | <!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默>认是true --> |
- 修改
conf/spark-env.sh,分发
1 | YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop |
- 测试(注意 master、deploy-mode 参数的变化)
1 | $ start-dfs.sh |
- spark-shell
1 | $ bin/spark-shell --master yarn |
6.4.2 spark-history-server
$HADOOP_HOME/etc/hadoop/yarn-site.xml 中添加
1 | <property> |
$SPARK_HOME/conf/spark-defaults.conf
1 | spark.yarn.historyServer.address hadoop102:18080 # spark history Server 物理机 |
- 相关服务
- spark:
sbin/start-all.sh - HDFS:
[hadoop102]$ start-dfs.sh - Yarn:
[hadoop103]$ start-yarn.sh - Yarn-history:
[hadoop104]$ mr-jobhistory-daemon.sh start historyserver - Spark-history:
[hadoop102] $ sbin/start-history-server.sh
- spark:
【可以正常展示了】
相关文档解释:spark深入:配置文件与日志 - Super_Orco - 博客园
- 查看方式
- 通过 YARN 查询
- 直接在 spark history server 中查询
6.5 WordCount 程序
略
6.6 pyspark 读取文件
1 | ./bin/pyspark |
python 程序
1 | #!/usr/bin/env python |
七、Hive 配置
7.1 单机默认配置
下载地址:http://archive.apache.org/dist/hive/
安装部署:
- 修改
conf/hive-env.sh.template
1 | $ mv hive-env.sh.template hive-env.sh |
- hadoop 相关配置
1 | # 启动 hdfs yarn |
- Hive 基本操作
1 | $ bin/hive |
7.2 修改默认数据库(derby -> MySQL)
derby 只支持单个客户端连接,仅适用于简单测试。更换成关系型数据库(如MySQL),可支持多客户端连接。
7.2.1 安装 MySQL
- 卸载原有的,安装新的 MySQL
1 | # 卸载原有的 |
- 配置 MySQL 远程登录
1 | $ mysql -uroot -p123456 |
7.2.2 修改 hive 元数据库
- 拷贝驱动
1 | $ cp mysql-connector-java-5.1.27-bin.jar /opt/module/hive-2.3.0-bin/lib/ |
- 配置 Metastore 到 MySQL
创建 conf/hive-site.xml
官方配置文档
AdminManual Metastore Administration - Apache Hive - Apache Software Foundation
1 |
|
用于启动 hive-metastore 的配置
1 | <property> |
- 启动
1 | # 初试化hive库 |
7.3 Beeline 连接
Hive学习之路 (四)Hive的连接3种连接方式 - 扎心了,老铁 - 博客园
https://www.cnblogs.com/qingyunzong/p/8715925.html
7.4 常用交互命令
1、-e不进入 hive 的交互窗口执行 sql 语句
1 | $ bin/hive -e "select id from student;" |
2、-f执行脚本中 sql 语句
- 创建 hivef.sql 文件
1 | $ touch hivef.sql |
7.5 集成 Tez 引擎
- 解压 tez:
/opt/module/tez-0.9.1-bin - 同时上传一个 tez 包到 hdfs,用于给集群中其他节点用
1 | hadoop fs -put /opt/software/apache-tez-0.9.1-bin.tar.gz/ /tez |
- 在 HIVE_HOME/conf 下创建
tez-site.xml
1 |
|
- 修改
hive-env.sh
1 | # Folder containing extra libraries required for hive compilation/execution can be controlled by: |
- 修改
hive-site.xml
1 | <property> |
- 测试
1 | # 启动Hive |
八、HBase 配置
8.1 集群配置
conf/hbase-env.sh
1 | # 1、注释掉下面两行 |
conf/hbase-site.sh
1 | <!-- 都要根据自己的机器进行配置 --> |
- 单独启动
1 | # 启动 HDFS、Zookeeper |
- 群起 / 群停
1 | # 启动 HDFS、Zookeeper |
- 进入 shell
1 | # 如果有 kerberos 认证,需要先 kinit 一下 |
8.2 常用操作
使用 help 查看各种命令使用方式
1 | # 列出所有指令 |
8.2.1 namespace
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
- list_namespace
1 | # 查看所有库名 |
- create_namespace
1 | > create_namespace 'school' |
- delete_namespace
1 | # 注意:只能删除空库 |
- list_namespace_tables
1 | # 列出库中所有表 |
8.2.2 DDL
Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, locate_region, show_filters
- list
1 | # list 列出所有表 |
- create
1 | # create '库名:表名', { NAME => '列族名1', 属性名 => 属性值}, {NAME => '列族名2', 属性名 => 属性值}, … |
- desc
1 | > desc 'student' |
- disable
1 | # 停用表,防止对表进行写数据;在修改或删除表之前要 disable |
- enable
1 | # 启用表 |
- alter
1 | # 需要先 disable |
- drop
1 | # 需要先 disable |
- count
1 | # 查看行数 |
- truncate
1 | # 删除表数据 |
8.2.3 DML
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
- scan
1 | # 查看数据 |
- put
1 | # put '表名', '行键', '列族:列名', '值' |
- get
1 | > get 'student','1001' |
- delete
1 | # 删除某rowkey的全部数据: |
8.2.4 其他操作
- flush
1 | # 将内存数据落盘 |
九、Flink 配置
9.1 Standalone 模式
1、准备安装包
1 | flink-1.10.1-bin-scala_2.12.tgz |
2、修改 conf/flink-conf.yaml 文件
1 | jobmanager.rpc.address: hadoop102 |
3、修改 conf/slaves 文件
1 | hadoop103 |
4、分发
5、启动
1 | ./bin/start-cluster.sh |
6、访问 http://localhost:8081 可以对 flink 集群和任务进行监控管理
7、提交任务
- web 模式
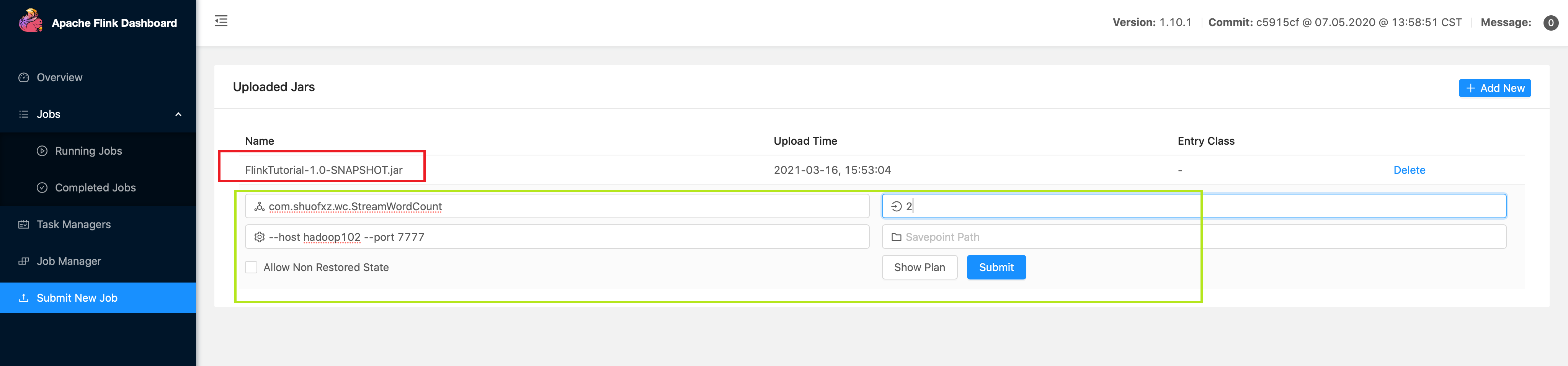
- 命令行
1 | ./flink run -c com.atguigu.wc.StreamWordCount –p 2 FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777 |